Soichiro Okazaki
Research & Development Group
Hitachi, Ltd.
Introduction
Natural disasters such as earthquakes, floods, fires and hurricanes can cause much damage and loss, posing significant risks to human lives, infrastructure, and the environment. While it is important to prevent or mitigate these disasters from occurring (i.e. pre-disaster approach), it is equally important to respond effectively to these disasters after they occur (i.e. post-disaster approach). One post-disaster approach is to quickly assess the disaster-affected areas to develop appropriate rescue and recovery plans, and helicopters and new technology such as drones are now being used to collect aerial footage to help for such assessments.
At Hitachi, we’ve been working on technologies to address this issue, using aerial footage with video analysis AI since around 2020. In this blog, I’d like to introduce a technology that we developed which achieved top-level recognition accuracy the TRECVID 2020 Disaster Scene Description and Indexing (DSDI) Task, a globally recognized disaster video analysis competition [1].
Understanding the TRECVID 2020 DSDI Task: A benchmark for disaster video analysis
Before moving on to describing the technology, let me explain what the DSDI task required. TRECVID, an annual video analysis workshop organized by the US National Institute of Standards and Technology (NIST) since 2001, serves as a forum to advance video analysis technologies. One of the key competitions in TRECVID 2020 was the DSDI task which focused on analyzing 32 predefined disaster attributes such as flooding, landslide, rubble, and smoke/fire, using approximately 40,000 labeled and 600,000 unlabeled aerial images provided to the participants. Below are examples of the aerial images:

How can we build a better disaster video analysis AI system?
Preliminary data analysis is a critical first step in building a machine learning model. As a first step, my team members and I took a closer look at the nature of the DSDI dataset using Exploratory Data Analysis (EDA), and identified three main key challenges:
- Noisy labels: The dataset contained inconsistencies such as missing or erroneous labels which could hinder model performance,
- Imbalanced data: Imbalanced distribution of disaster attributes creating a challenge for unbiased model training, and
- High-resolution complexity: Attributes of varying sizes necessitating efficient processing of high-resolution data.
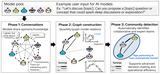
To address these challenges, we developed a three-part solution:
- Applying label encoding techniques to smooth the multiple annotations to reduce the noisy label propagation,
- Incorporating various training losses based on Focal Loss[2] to tackle the imbalanced data distribution and
- Leveraging the latest (as at 2020) proposed efficient network architectures to deal with the high-resolution images.

The inference results from the above solution, achieved top-level disaster recognition accuracy in the DSDI Task.

The images in Figure 4 below show the solution’s ability to localize disaster attributes using post-processed heat maps generated by Grad-CAM [3] & Grad-CAM++ [4]. As you can see, the results indicate how the solution can appropriately capture the presence and location of the disaster attribute.

Conclusion
In addition to the technologies described above, we are integrating recent developments such as multi-modal foundation models, large language models (LLMs), and other state-of-the-art video analysis AI technologies, to further enhance our disaster video analysis systems. By collaborating with partners across various sectors, we aim to build a system that enables rapid and precise disaster assessments – an essential capability for saving lives and accelerating recovery efforts.
Acknowledgements
This work is a cooperation with team NIIICT and NII UIT. My colleagues and I would like to express our appreciation to Dr. Shoichiro Iwasawa et al. from NIIICT for providing their AutoML solution as a part of the fusion system, and the advice and support we received from Dr. Shin’ichi Satoh of team NII UIT on the technique and system submissions. In closing, I would also like to acknowledge the members of the Hitachi team, Quan Kong, Martin Klinkigt and Tomoaki Yoshinaga, who contributed to this development and our achievement in TRECVID DSDI 2020.
References
[1] S. Okazaki, Q. Kong, M. Klinkigt, and T. Yoshinaga. Hitachi at TRECVID DSDI 2020. In TRECVID 2020 Workshop, 2020.
https://www-nlpir.nist.gov/projects/tv2020/tv20.workshop.notebook/tv20.papers/vas.pdf
[2] T.Y. Lin, P. Goyal, R.B. Girshick, K.M. He, and P. Doll´ar. Focal loss for dense object detection. In IEEE International Conference on Computer Vision (ICCV), 2017.
[3] R.R. Selvaraju, M. Cogswell, A. Das, R. Vedantam, D. Parikh, and D. Batra. Grad-cam: Visual explanations from deep networks via gradient-based localization. In IEEE International Conference on Computer Vision (ICCV), 2017.
[4] A. Chattopadhay, A. Sarkar, P. Howlader, and V.N. Balasubramanian. Grad-cam++: Generalized gradient-based visual explanations for deep convolutional networks. In IEEE winter conference on applications of computer vision (WACV), 2018.