Two researchers reunite at the Digital Observatory
Matsuda: I chose to study in the Department of Electrical, Electronic, and Communication Engineering in university to develop a broad range of knowledge. In my undergraduate and graduate studies, I researched electromagnetic waves, but the idea of studying only electromagnetic waves for my whole career didn’t quite feel right. During my job search, I discovered that Hitachi is a company involved in an impressively wide range of fields. I decided to join with the expectation that I could take on research challenges in different fields if I wanted to change my research focus.

Tomohiro MATSUDA, Senior Researcher, Digital Observatory Project, Next Research, Research & Development Group, Hitachi, Ltd.
I was initially assigned to a department researching networks. There, I contributed to Hitachi’s business through technology development for improving mobile communication quality. But as the company restructured its businesses, my research field changed, and I spent about five years working on robotics development. Afterward, I did research on data collection and utilization for buildings and factory IoT systems. Since 2025, I’ve been working on the Digital Observatory, which monitors digital information, conducting research on identification and early-warning detection of social risks through data observation.
Hitachi has a culture that enables you to take on challenges in fields different from your previous work if you’re serious about it. That makes it easy to maintain motivation and creates an environment that encourages taking on new challenges. It’s definitely one of the reasons I’ve been able to continue at Hitachi without ever feeling bored with my work.
Mizushina: I actually graduated from the same university and department as Matsuda, and we’d known each other even before I joined the company—he was my recruiter. During my student days, I researched semiconductor technology, specifically analyzing error patterns and error correction in NAND flash memory. When I entered graduate school, deep learning for image recognition was gaining momentum. I got into the exciting industrial applications bridging computer vision and semiconductors, which sparked my interest in working as a researcher in the private sector. While Matsuda was technically the one who brought me to Hitachi, there were other factors: having many senior colleagues who had joined the company and being impressed by Hitachi’s broad business domains and the wide-ranging capabilities that emerged from them, for example. I was also excited about seeing my research results applied in practical settings. Altogether, that’s what led me to work at Hitachi.

Keita MIZUSHINA, Senior Researcher, Digital Observatory Project, Next Research, Research & Development Group, Hitachi, Ltd.
When I first joined, I was in charge of data analysis. My job was to analyze error patterns to predict failures in manufacturing machinery for medical equipment. The research results led to successful proof of concept (PoC) implementations. Later, I worked on Common Ground research connecting physical and digital spaces, developing applications that closely link physical and virtual spaces to enable real-time interaction between them.
Later, with the establishment of the Institute for Digital Observatory, I was invited to participate as a joint researcher in the Digital Observatory project in collaboration with the University of Tokyo. I still remember how excited I was, understanding that this collaboration with the university would allow us to apply the Digital Observatory across various fields with a global perspective.
Visualizing potential risk information to extract insights
Mizushina: The University of Tokyo established its Institute for Digital Observatory in April 2023. The Digital Observatory makes a wide range of social and economic activities observable as digital data, enabling early detection of risk signs of natural disasters or climate change, guiding countermeasures, and facilitating recovery and avoidance actions. Based on news, social information, statistical data, and other factors, it predicts what events are causing damage to what.
Hitachi has also been engaged in research on data management platforms alongside its deep involvement with social infrastructure. That’s why, in this collaborative research, we decided to focus specifically on improving supply chain resilience.
As the topic is grabbing more and more attention—with even the Ministry of Economy, Trade and Industry discussing supply chain risks in the Study Group on Advancing Global Supply Chains in the Digital Age—we thought it would be effective to pursue research by involving divisions that operate in the field of supply chain management.

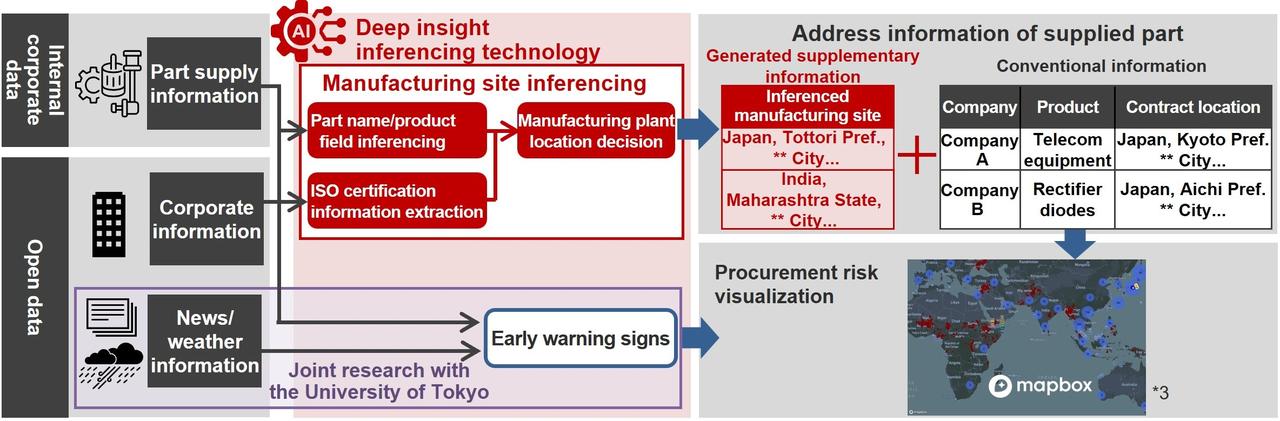
Supply chain risks include natural disasters such as earthquakes and floods, pandemics, port strikes, human rights issues, and various other factors. For example, if a river floods, factories in the affected basin may shut down, impacting the supply chain. To gain relevant insights, we need to match geographic risk distribution with the locations of our company’s suppliers. By understanding which factories supply which products in which regions and matching that knowledge with risk information, we can assess risks effectively.
However, in actual supply chains, suppliers’ factory locations and other geospatial information are often difficult to obtain. Even when you research product suppliers, you often only find headquarters addresses like Chuo-ku or Minato-ku in Tokyo—there tends to be little to no information about the factories actually manufacturing the parts. Additionally, for parts purchased through trading companies or other parties, it is sometimes impossible to confirm information directly with manufacturers that actually make items. Until now, the only way to match risks with locations was for procurement personnel to deal with the manufacturers directly and get the necessary geographical information. Through interviews with field staff, we discovered that if we could reduce this workload through partial automation, procurement personnel could focus on their core responsibilities.

Creating a single product requires thousands of different parts. If a company offers hundreds of product models, that means thousands of parts multiplied by hundreds of models are being sourced through the supply chain. Procurement personnel have to research information on parts by making phone calls and other inquiries. Even if they were able to create a complete dataset of location information, product improvements or changes in manufacturing facilities due to discontinued parts would turn that work into a never-ending game of cat and mouse. That’s why Hitachi has developed a system to estimate the locations of parts-manufacturing plants, enabling the automation of information gathering. For this, we use deep insight inferencing technology that extracts insights from diverse data sources in ways that go beyond human capabilities.
Boosting accuracy to around 60% significantly improves efficiency
Mizushina: The ultimate goal of our technology is to accurately estimate which companies we’re buying from, what we’re buying, and where it’s being manufactured. Companies possess information about parts suppliers, but contract information typically only includes addresses of the headquarters, not the actual manufacturing locations. When we examined actual data, we found that information about factory locations was available for only about 30% of cases. Through interviews with procurement personnel, we learned that if this could be increased to about 60%, work efficiency would improve dramatically. So we developed deep insight inferencing technology to estimate parts-manufacturing factories using publicly available information, such as corporate data and certification information.
Overview of manufacturing industry supply-chain risk mitigation
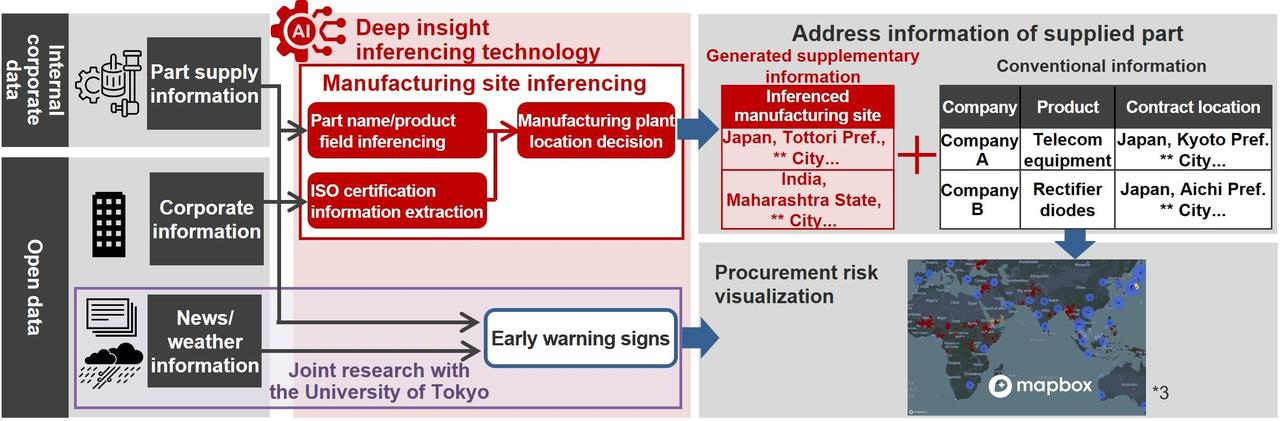
First, regarding corporate information, company websites often publish details about their facilities such as factories and logistics centers. However, the format can vary: a company might use text, PDF, images, or pins on map applications. Our success in improving accuracy, I think, came from adopting a specialized large language model (LLM) to process various patterns of unstructured information into structured data categorized by factory addresses, product types, and other attributes.
Meanwhile, companies actively disclose information on ISO certification, which is an international qualification for quality management demonstrating an organization’s ability to consistently provide products and services. This includes information such as which facilities have obtained certification and what types of products they manufacture. Although the data is standardized by ISO, the format varies, making it difficult to structure the information using conventional natural language processing. By using an LLM to organize and structure various types of data into a unified format, we made it possible to derive relationships between parts and factories from open data.
We used generative AI in one more area: the matching of part names in procurement information with ISO information. Information on parts is managed in a way that procurement personnel can understand, with the names of parts like H-beams, screws, aluminum and steel materials, and so on all listed. But ISO certification information focuses on describing the main function of the certified facility, such as “steel manufacturing” or “assembly,” causing a disparity in information granularity. It’s also not uncommon for the same part to have different names at different companies. Therefore, we mapped to a systematically organized code system to clarify which parts correspond to which ISO product codes. Since LLMs don’t inherently have knowledge to map part names to coding systems, we fine-tuned (additional training) the LLM. This alignment of granularity between part names and ISO certification information enables data matching, which helps estimate factory locations.
Method of manufacturing site inferencing
With deep insight inferencing technology, we generate candidate manufacturing sites based on inference. Since procurement personnel have extensive knowledge of and experience with supplier companies and parts, combining the multiple candidates generated with the expertise of procurement personnel enables humans and LLMs to collaborate for highly accurate estimations. Also, by accumulating the selection history and tendencies of procurement personnel, the system becomes smarter the more it’s used.
A paper summarizing our research and development on deep insight inferencing technology was accepted at the 8th ACM SIGSPATIAL International Workshop on AI for Geographic Knowledge Discovery.
Developing AI that is smart and safe, learning from operational insights
Mizushina: Beyond technology development, we’re also incorporating features to encourage adoption in actual workplace settings. Since we made the LLM used for estimation function on an entirely local basis, users can feel comfortable inputting information—even confidential information—into the system. This is because we considered the security risks associated with using external AI models. Hitachi has manufacturing sites in addition to IT and OT capabilities, with many specialists in various fields across the company. We also know that systems only provide value when they’re actually used. By demonstrating that the system is secure and becomes smarter through use, we believe we can accumulate valuable insights from the front lines.
We’ve also considered ensuring reproducibility. New open AI models are constantly emerging, and the same input might yield different answers. However, our system for generating potential manufacturing sites needed to provide consistent answers to the same questions. Therefore, we designed multiple AI agents to mutually monitor inputs and outputs, ensuring a consistent quality of responses.
When we began developing this estimation technology around 2023, there was no framework for agentic AI where multiple AI agents could collaborate, so we hand-crafted a mechanism for AI cooperation to ensure response quality.
Through these combined technologies, we were able to estimate supplier manufacturing site information at over 85% accuracy in cases using procurement department information within the Hitachi Group. Since we were using internal group data and knew the correct locations for supplier manufacturing sites, we could confirm the system’s high accuracy levels. Our collaborators at the University of Tokyo gave us positive feedback, saying they hadn’t expected that the data would be estimated at such a high accuracy level.
Integrating with risk countermeasure applications
Matsuda: The manufacturing site estimation technology that Mizushina developed presents data as numbers and text. To make this technology usable in procurement departments and other operational settings, we needed to add application features like a GUI and refine the ways to display the basis of information. I’ve been in charge of that development.
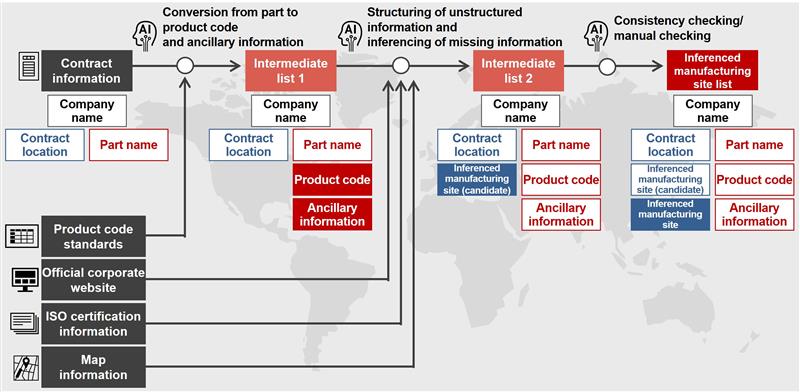
Distribution map of corporate information (blue dots represent facility locations)
Left: Headquarters concentrated in urban areas; Right: All facilities (including manufacturing sites) distributed broadly
For the personnel who actually use it, we needed to provide insights from the data in an accessible way. Also, given that users won’t use a system that loads too slowly because of massive amounts of data, we reduced the amount of data loaded for the initial screen display to ensure smooth startup. By displaying inferenced manufacturing sites for each part on a map, the system gives users a visual grasp of things like where manufacturing sites are concentrated. Combined with risk signs extracted from news and weather conditions through our joint research with the University of Tokyo, if manufacturing sites are concentrated in regions with typhoon or earthquake risks, adjustments can be made so that the company can source items from manufacturing sites in different regions.
Another aspect we considered was operational: whether the information that the application shows is credible and whether the system is functioning properly. Since people won’t use the system if we can’t provide reliable information, we developed the application with long-term use in mind.
Mizushina: We need to show users what evidence the information is based on and when the data was collected. Also, different users have different points of interest depending on their roles—like procurement, business continuity planning (BCP), finance, or customs. I asked Matsuda to organize and develop the kinds of screens that would be necessary for different users. While I could provide data, I often hadn’t thought through the application development needed for actual operation. I’ve been receiving a lot of guidance from Matsuda in that respect.
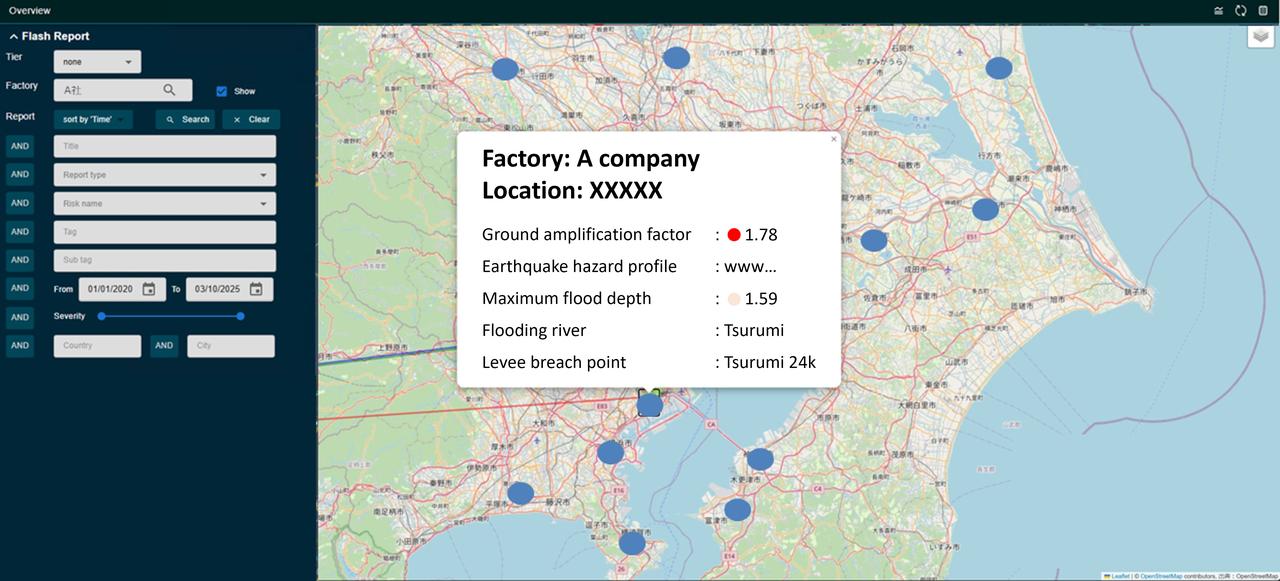
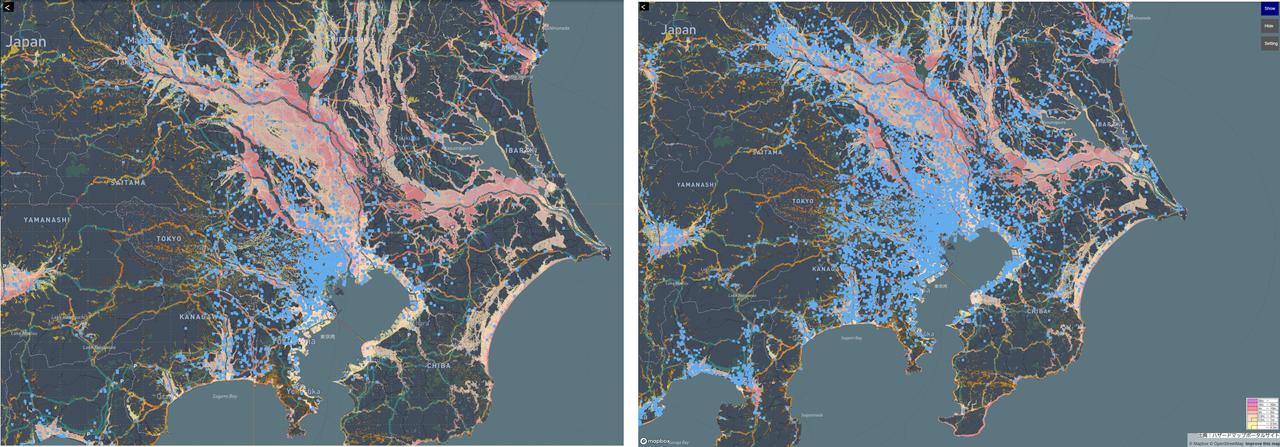
Example of supply chain risk visualization using deep insight technology
With visual representations of the correlation between risks and manufacturing sites, users can understand where the parts their company uses are made and develop a stronger awareness of the relationships between parts and risks. During verification, we heard comments like, “We recently changed suppliers, but the new one was also in a flood zone. We wish we’d known the risk correlation earlier.” That feedback suggests that those in the field appreciate the ability to identify inferenced manufacturing sites.
Improving accuracy and adding suggestion features for risk avoidance
Matsuda: Currently, we’re developing an application that clearly displays on a map which portions of the supply chain face significant risk. In the future, we’ll add features that suggest possible countermeasures for current risks, beyond just displaying risks and manufacturing sites. The application will provide concrete suggestions on supplier changes to make. Looking further ahead, we believe that the application’s ability to highlight early signs of future risks can help in considering future procurement sources.

Mizushina: The accuracy we achieved in tests within the Hitachi Group—over 85%—is quite high compared to our initial target for enabling practical use, which was 60%. From a technical standpoint, though, we want to improve accuracy even further. We should be able to improve accuracy if we can put the system to use in various industries and incorporate user feedback to make it even smarter. From a supply chain risk-management perspective, we’ve just reached the point where geographical information can be estimated with high accuracy. Now that we can identify where to look for risks, we’re moving to the stage of estimating and evaluating signs of risk. We want to further expand the value of the Digital Observatory by gaining insights on how we can connect geographical and risk information from University of Tokyo faculty members and in-house specialists.

Tomohiro MATSUDA
Senior Researcher
Digital Observatory Project, Next Research
Research & Development Group, Hitachi, Ltd.
The classic that inspired a boy who dreamed about future space to become a researcher
The novelization of Star Wars (by George Lucas and others, Kodansha) that I started reading in junior high made a lasting impact on me. Star Wars features people from various planets, includes many robot characters, and uses lots of futuristic technologies. It presents a world full of diversity. The book sparked my interest in future technologies, and when I got started in actual robot development, I was building with R2-D2 and C-3PO from Star Wars in mind. Episode IV: A New Hope is the one that has really stayed with me. Parts of what I thought was just a fantasy when I first read it have now become reality, something I still find fascinating.

Keita MIZUSHINA
Senior Researcher
Digital Observatory Project, Next Research
Research & Development Group, Hitachi, Ltd.
Finding inspiration in scholars who connect their expertise to broader knowledge
I’d like to tell you about Chi no gyakuten (Beyond wisdom, NHK Publishing). It’s a book compiling interviews with six people; one is James Watson, who discovered the double helix structure, and another is Noam Chomsky, who proposed the generative grammar concept that greatly influenced linguistics. I had liked Chomsky for some time and found this book when I was a high school senior aiming to research generative grammar. I was impressed that each person, while a renowned expert in their field, also had deep interest and knowledge outside their specialty and could discuss various topics by connecting them to their expertise. This book made me want to be like that when I grew up. Although I researched semiconductors in graduate school, I’m now working with generative AI through a winding path, and I feel a connection to generative grammar.
(Photo by Kiyono Hattori)