Achieves false-positive suppression and false-negative reduction in manufacturing sites, social infrastructure, and more
Hitachi has developed an AI technology that post-processes and corrects the detection results of existing object detection AI to enhance safety and operational efficiency across a wide range of fields, including manufacturing sites and social infrastructure. Conventional approaches have struggled to fully capture the relationships between global contextual information (information from the image as a whole) and region-specific detailed information. The newly developed technology overcomes this challenge by enabling integrated analysis of both types of information, thereby providing more accurate correction of detection results in images and videos. Evaluation using multiple public benchmarks*1 confirmed detection-accuracy improvements of more than 50% in some cases involving application of the technology to state-of-the-art object detection models.*2 In addition, the technology requires only approximately 0.1 seconds of additional processing time per image,*3 achieving both higher accuracy and efficient processing. Because the technology corrects detection results without requiring retraining or modification of the underlying AI model, it can also be applied to black-box AI systems accessed through APIs.*4 As a result, organizations can continue utilizing their existing object detection AI and achieve false-positive suppression and false-negative reduction in situations involving unknown objects or complex environments.
Going forward, Hitachi will position the technology as one supporting Lumada 3.0 and contribute to the realization of a safe, secure, and sustainable society by advancing image-recognition capabilities in fields such as manufacturing, facility maintenance, infrastructure monitoring, and aerial-image analysis.
*1 General image datasets widely used for object detection tasks, including COCO, LVIS, ODinW13, and Pascal VOC.
*2 Object detection models such as Grounding DINO and LLMDet that can detect arbitrary objects in images based on text prompts.
*3 Performance measurement results obtained using a standard PC environment (CPU: Intel® Core™ i9; GPU: RTX 2080 Ti).
*4 API (Application Programming Interface): A set of interfaces and rules that enable different software applications to exchange data and functions.
Background and issues
The use of object detection AI to identify objects in images and videos is expanding across a variety of fields, including product inspection in manufacturing environments, facility maintenance, infrastructure monitoring, and aerial-image analysis. Detection results in these applications must be highly reliable, as they directly affect quality assurance, safety, and stable operations. However, there is always a risk of false positives and false negatives due to factors such as unknown objects, the presence of many visually similar objects, complex background information, and environmental changes over time. To address these issues, methods for correcting detection results have come into use. Conventional approaches, however, have faced difficulties in accurately correcting detection results based on the relationships between global image information and fine-grained region-level information. In addition, some methods require the retraining or modification of existing object detection AI models. As a result, there has been a growing need for a technology that can be applied to a wide range of object detection AI models without any modification to the existing system and simultaneously achieve both false-positive suppression and false-negative reduction.
Features of the technology
To address these challenges, Hitachi developed an AI technology that leverages the outputs of existing object detection AI and performs integrated analysis of both the global contextual information from the entire image and fine-grained region-level information to correct detection results at a high degree of accuracy. The key features of the technology are described below.
1. Detection result–correction technology that achieves both false-positive suppression and false-negative reduction
The technology first uses a feature extraction module to extract important information from an image, obtaining both global image features and region-level features. Next, these features are fed into a feature fusion module, which analyzes the relationships between global and region-level information. The module is trained to use the analysis results to generate both a global prediction, which determines what the entire image represents, and a region-level prediction, which determines what each detected region represents. Finally, these prediction results are combined with the original object detection outputs to produce more accurate detection results. This approach enables correction based on simultaneous consideration of both the overall image context and individual detection results, something that has been difficult to achieve using conventional methods. As a result, the technology both suppresses false positives and reduces false negatives.
2. Model-agnostic design that can be added to various object detection AI systems
The technology uses only the input image and the outputs of object detection AI (predicted label information and coordinate information for detected regions) during processing. As processing relies solely on these inputs, the technology is independent of the AI model’s internal architecture and trained parameters, enabling deployment without retraining or modification of the original model. As a result, the technology can be added not only to conventional object detection AI systems with public source code but also to black-box AI systems, including AI services such as generative AI platforms that are accessible only through APIs and do not allow access to their internal architecture or parameters. This model-agnostic design enables organizations to continue using their existing image-recognition systems while enhancing the accuracy of object detection across a wide variety of AI platforms.
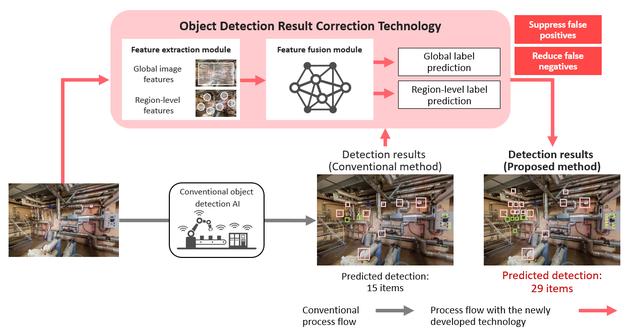
Figure 1. Overview of the AI technology that corrects detection results from object detection AI
by simultaneously utilizing global image features and region-level features (conceptual image)
Confirmed results
Evaluation of the technology using multiple public benchmarks demonstrated consistent accuracy improvements across a variety of state-of-the-art object detection models, including Grounding DINO and LLMDet. The technology achieved detection-accuracy improvements of more than 50% compared with the original object detection models in some cases. Applying the technology to each object detection AI model requires only approximately 0.1 seconds of additional processing time per image, which indicates that it performs processing efficiently in addition to improving accuracy. As a result, the technology can maintain stable detection performance even in environments involving previously unseen objects or complex conditions, making it suitable for deployment in a wide range of real-world applications.
Looking ahead
Going forward, Hitachi will position the technology as one supporting Lumada 3.0 and promote its deployment across a broad range of fields, including manufacturing, facility maintenance, infrastructure monitoring, and aerial-image analysis. By improving detection accuracy while leveraging existing image-recognition systems, Hitachi aims to support workplace safety and enhance operational efficiency. In addition, it will continue advancing technologies tailored to individual operational environments and use cases and promoting integration with other AI technologies to establish a more reliable foundation for image recognition. Through these efforts, Hitachi will accelerate digital transformation across social infrastructure and industrial sectors and contribute to the realization of a safe, secure, and sustainable society.
A portion of these research findings will be presented in the Findings Track of CVPR 2026 (The IEEE/CVF Conference on Computer Vision and Pattern Recognition 2026), to be held from June 3 to June 7, 2026.*5
*5 Soichiro Okazaki, Tatsuya Sasaki, Hiroki Ohashi, “DetRefiner: Model-Agnostic Detection Refinement with Feature Fusion Transformer”, CVPR 2026 (Findings), 2026.
For more information, use the inquiry form below to contact the Research & Development Group, Hitachi, Ltd. Please make sure to include the title of the article.
https://www8.hitachi.co.jp/inquiry/hitachi-ltd/hqrd/news/en/form.jsp